Prediksi Kualitas Red Wine menggunakan Random Forest

Setiap jenis wine yang berbeda akan memiliki konsentrasi zat kimia yang berbeda juga. Untuk menjaga kualitas dengan biaya rendah, penting untuk mengetahui kandungan konsentrasi zat kimia yang digunakan dalam berbagai jenis wine [1].
Pendekatan manual untuk mengidentifikasi kualitas wine membutuhkan waktu yang lama dan memiliki tingkat akurasi yang rendah [2]. Dan dengan menganalisa kandungan konsentrasi zat kimia dapat kita peroleh cara untuk membedakan kualitas wine.
Eksplorasi Data Analisis
Data yang digunakan untuk proyek ini adalah Red Wine dataset yang diunduh dari dataset Kaggle. Dataset tersebut memiliki jumlah data sebanyak 1599 baris dengan 11 fitur dan 1 target. Untuk penjelasan variabel-variabel pada dataset Red Wine dapat dilihat pada poin-poin berikut:
-
fixed acidity: kandungan asam yang bersifat sudah tentu -
volatile acidity: kandungan asam yang bersifat volatile -
citric acid: kandungan asam sitrat -
residual sugar: jumlah kandungan gula residual karena proses fermentasi -
chlorides: kandungan garam pada wines -
free sulfur dioxide: kandungan SO2 dalam bentuk kesetimbangan antara molekul SO2 (sebagai gas terlarut) dan ion bisulfit -
total sulfur dioxide: jumlah keseluruhan S02 -
density: tingkat kerapatan cairan -
pH: menggambarkan seberapa asam atau basa anggur dalam skala dari 0 (sangat asam) hingga 14 (sangat basa) -
sulphates: kadar aditif wines yang dapat berkontribusi pada tingkat gas sulfur dioksida (S02) -
alcohol: persentase kandungan alkohol pada wines -
quality: variabel output berdasarkan data sensorik dengan skor dari 0 sampai 10
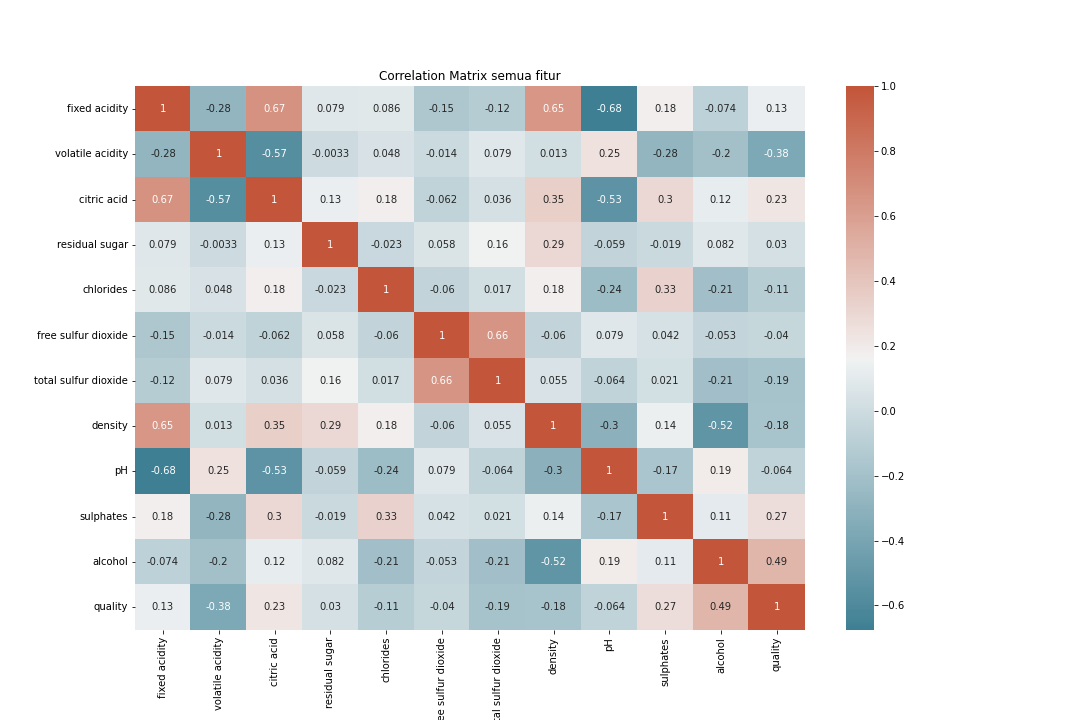
Berdasarkan plot heatmap korelasi diatas, fitur yang memiliki korelasi diantara -0.1 sampai 0.1 dengan fitur quality adalah residual sugar, free sulfur dioxide, dan pH. Oleh karena itu fitur tersebut nantinya dapat dibuang.
Preprocessing Data
Tahap berikutnya adalah preprocessing data, tahap dimana data akan diolah sehingga sudah siap untuk proses pemodelan Dan berikut adalah tahapan dalam preprocessing data:
Outliers
Menghapus data yang memiliki outlier di lebih dari 3 fitur. Outliers sendiri dapat mempengaruhi performa dari model.
# Membuat Fungsi Untuk Mendeteksi Baris yang memiliki lebih dari 2 outliers pada kolomnya
def detect_outliers(df, features):
outlier_indices = []
for f in features:
# Quartile Pertama
Q1 = df[f].quantile(0.25)
# Quartile Kedua
Q3 = df[f].quantile(0.75)
# Interquartile Range
IQR = Q3 - Q1
# Deteksi outlier beserta index barisnya
outlier_list_col = df[((df[f] < Q1 - 1.5 * IQR)|(df[f] > Q3 + 1.5 * IQR))].index
# Menambahkannya kedalam list
outlier_indices.extend(outlier_list_col)
# Menghitung jumlah outlier untuk tiap index
outlier_indices=Counter(outlier_indices)
# Memilih index yang memiliki outlier lebih dari 2
multiple_outliers = list(i for i, v in outlier_indices.items() if v > 2)
return multiple_outliers
# Melakukan drop outlier wines = wines.drop(detect_outliers(wines,cols),axis = 0).reset_index(drop = True) wines.shape
Merestrukturisasi Data
Mengelompokkan data quality menjadigooddannot good, dimana data yang memiliki label good merupakan red wine yang baik
untuk kesehatan. Data yang memiliki nilai quality 0 sampai 6 merupakan
wine dengan kualitas not good. Sedangkan data yang memiliki nilai
quality 7 sampai 10 merupakan wine dengan kualitas good.
# Membuat fitur klasifikasi good dan not good pada fitur quality
wines['good_quality'] = [1 if n > 6.5 else 0 for n in wines['quality']]
# Melihat proporsi klasifikasi
plt.figure(figsize=(12, 6))
sns.countplot(x="good_quality", data=wines, palette='husl');
plt.title('Proporsi Good Quality')
Distribusi data setelah dilakukan pengelompokan data adalah seperti berikut,

# Memisahkan fitur dan target
X = wines.drop(['quality', 'good_quality', 'residual sugar', 'free sulfur dioxide', 'pH'], axis = 1)
y = wines['good_quality']
Split Data
Membagi dataset menjadi dat train dan data test dengan rasio 80% untuk data train dan 20% untuk data test. Dimana data train digunakan untuk melatih model, sedangkan data test merupakan data yang digunakan untuk menguji model setelah melalui pelatihan data.
# Membagi train dan test dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 610)
Standarisasi
Standarisasi pada semua fitur dataset. Standarisasi yang dilakukan adalah menggunakan teknik StandardScaler, dimana data akan dikurangi dengan nilai rata-rata kemudian dibagi dengan standar deviasi, sehingga dataset akan memiliki standar deviasi sebesar 1 dan rata-rata sama dengan 0.
# Standarisasi Fitur scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test)
Modelling
Model baseline
Pada langkah ini dibuat sebuah model Random Forest dengan library scikit-learn RandomForestClassifier. Dalam pemodelan ini model dibuat tanpa parameter tambahan.
# Pelatihan model baseline
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
Tuning Hyperparameter
Dilangkah ini model baseline yang sudah dibuat kemudian dikembangkan kinerjanya. Untuk meningkatkan kinerja model maka dilakukan pencarian hyperparameter yang optimal untuk model dengan GridSearchCV. Setelah ditemukan hyperparameter terbaik dari prose GridSearchCV, kemudian parameter tersebut diterapkan ke model baseline.
# Hyper parameter yang akan dituning
params_rf = {'n_estimators':[5,10,15,20,25,30,40,50],
'max_depth':[1,3,5,7,9,11,13,15,17],
'max_features':['log2','sqrt']}
# Pencarian parameter terabaik dengan Grid Search CV
rf = RandomForestClassifier()
grid_rf = GridSearchCV(estimator = rf,
param_grid = params_rf,
cv=3,
scoring = 'accuracy',
verbose = 1,
n_jobs = -1)
grid_rf.fit(X_train, y_train)
y_pred = grid_rf.predict(X_test)
# Hasil tuning hyperparameter dengan skor terbaik yang didapatkan
print(f"Best Parameter : {grid_rf.best_params_}")
print(f"Best Score : {grid_rf.best_score_}")
Evaluasi Model
Model yang telah dibuat kemudian dilakukan evaluasi. Karena model merupakan tipe klasifikasi, maka evaluasi akan menggunakan metrics akurasi, f1-score, presisi, dan recall.
rf = RandomForestClassifier(max_depth = 13, n_estimators = 10, max_features='sqrt')
rf.fit(X_train, y_train)
# Pengujian Model Terhadap Test Dataset
y_pred = rf.predict(X_test)
# Hasil klasifikasi tuning model
tm_report = classification_report(y_pred,y_test,output_dict=True, target_names=['Not Good','Good'])
pd.DataFrame(tm_report).transpose()
Hasil evaluasi pada model baseline dan model tuning adalah sebagai berikut.

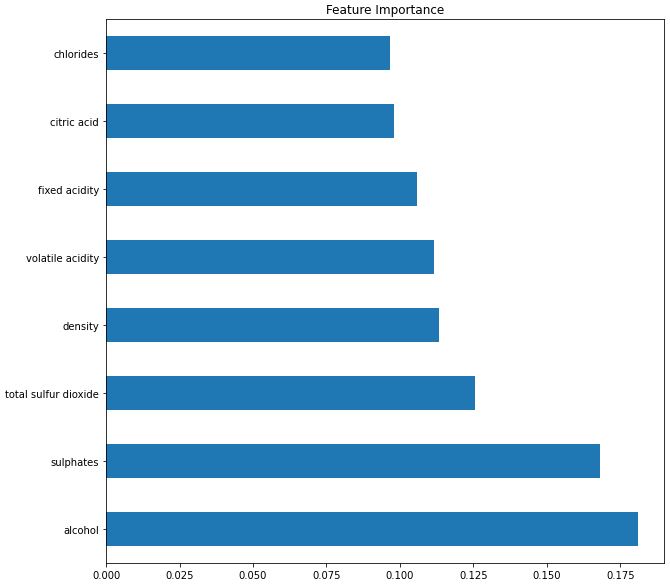
Kemudian untuk mencari fitur yang paling berpengaruh, mari kita visualisasikan feature importances dari model,
Referensi
-
[1] V. Preedy, and M. L. R. Mendez, “Wine Applications with
Electronic Noses,” in Electronic Noses and Tongues in Food Science,
Cambridge, MA, USA: Academic Press, 2016, pp. 137-151.
-
[2] P. Shruthi, “Wine Quality Prediction Using Data Mining,” 1st
Int. Conf. Adv. Technol. Intell. Control. Environ. Comput. Commun.
Eng. ICATIECE 2019, pp. 23–26, 2019, doi:
10.1109/ICATIECE45860.2019.9063846.
[1] V. Preedy, and M. L. R. Mendez, “Wine Applications with
Electronic Noses,” in Electronic Noses and Tongues in Food Science,
Cambridge, MA, USA: Academic Press, 2016, pp. 137-151.
[2] P. Shruthi, “Wine Quality Prediction Using Data Mining,” 1st
Int. Conf. Adv. Technol. Intell. Control. Environ. Comput. Commun.
Eng. ICATIECE 2019, pp. 23–26, 2019, doi:
10.1109/ICATIECE45860.2019.9063846.
Join the conversation