Sistem Rekomendasi Musik Spotify Menggunakan Content Based Filtering
Hlo semus, kali ini saya akan membahas tentang projek yang telah saya buat. Data dan sumber referensi nanti akan saya cantumkan sekalian, beserta alamat github projek ini.

Sekilas Ulasan Proyek
Proyek berupa sistem rekomendasi musik yang ditunjukkan bagi pengguna
aplikasi Spotify. Sistem rekomendasi musik ini menggunakan
pendekatan content-based filtering. Sistem rekomendasi adalah algoritma yang digunakan untuk membuat saran
yang akurat berdasarkan preferensi atau kebutuhan pengguna [1]. Content-based filtering melakukan rekomendasi dengan mempelajari kesamaan item konten yang
telah dipilih pengguna [2].
Musik telah menjadi salah satu seni yang disenangi oleh masyarakat di seluruh dunia. Musik datang dalam berbagai genre, seperti rock, klasik, tradisional, pop, dan banyak lagi. Evolusi teknologi dalam musik saat ini memudahkan pecinta musik untuk mengakses lagu dari aplikasi yang tersedia. Salah satunya adalah aplikasi Spotify.
Spotify adalah aplikasi pemutar musik yang menyediakan berbagai lagu dari berbagai kategori dan popularitas. Pengguna dapat mendengarkan artis dan genre favorit mereka dengan aplikasi Spotify ini.
Karena banyaknya musik yang terdapat pada Spotify terkadang pengguna bingung untuk memilih yang cocok dengan seleranya. Dan jika hanya mendengarkan lagu yang sama terus-menerus akan timbul rasa bosan. Oleh karena itu dibuatlah sistem rekomendasi ini untuk merekomendasikan pengguna terkait lagu yang sesuai dengan seleranya.
Pemahaman Dari Segi Implementasi
Rumusan Masalah
Berdasarkan uraian dari ulasan proyek yang telah dijelaskan sebelumnya, maka dapat diperoleh rumusan masalah :
- Bagaimana penggunaan content-based filtering untuk sistem rekomendasi musik?
Tujuan dari proyek yang dikerjakan adalah :
- Membuat sistem rekomendasi dengan menggunakan content-based filtering
- Melakukan penerapan metriks presisi untuk melihat performa dari rekomendasi sistem
Solusi untuk menyelesaikan permasalahan berdasarkan tujuan proyek adalah
:
- Melakukan pengolahan data pada tahap data preparation untuk meningkatkan presisi rekomendasi
- Menggunakan pendekatan cosine similarity untuk rekomendasi berdasarkan content-based filtering
Eksplorasi Data
Data yang digunakan untuk proyek kali ini adalah 19,000 Spotify Song yang diunduh dari Dataset Kaggle.
Dataset itu memiliki 2 buah file, yaitu song_data.csv dan song_info.csv. song_data.csv berisi informasi yang berkaitan tentang atribut audio lagu. Sedangkan song_info.csv berisi informasi yang berkaitan tentang metadata lagu.
Untuk proyek kali ini kita hanya akan menggunakan song_info.csv_. song_info.csv memiliki jumlah data sebanyak 18835 baris dengan 4 kolom, kolom
yang dimaksud adalah song_name, artist_name, album_names, dan playlist yang bertipe sebagai object. Untuk penjelasan tentang
variabel-variabel kolom tersebut, dapat dilihat pada poin-poin berikut
:
-
song_name: Judul lagu yang tertampil -
artist_name: Nama penyanyi yang menyanyikan lagu tersebut -
album_names: Nama album dimana lagu tersebut termasuk sebagai koleksinya, album sendiri adalah koleksi lagu dari suatu penyanyi -
playlist: Kumpulan lagu yang memiliki suatu kesamaan
Dari hasil eksplorasi unique value untuk tiap variabel kolom,hasilnya adalah sebagai berikut :
# Melihat jumlah lagu yang ada pada dataset
print("Jumlah lagu yang ada dalam dataset : ", len(song_info.song_name.unique()))
Hasilnya jumlah lagu yang ada dalam dataset adalah 13070
# Melihat jumlah artis yang ada pada dataset
print("Jumlah Penyanyi dalam dataset : ", len(song_info.artist_name.unique()))
Hasilnya jumlah penyanyi dalam dataset adalah 7564
# Melihat jumlah album dalam dataset
print("Jumlah Album dalam dataset : ", len(song_info.album_names.unique()))
Hasilnya jumlah album dalam dataset adalah 12014
# Melihat jumlah playlist dalam dataset
print("Jumlah Playlist dalam dataset : ", len(song_info.playlist.unique()))
Hasilnya jumlah playlist dalam dataset adalah 300
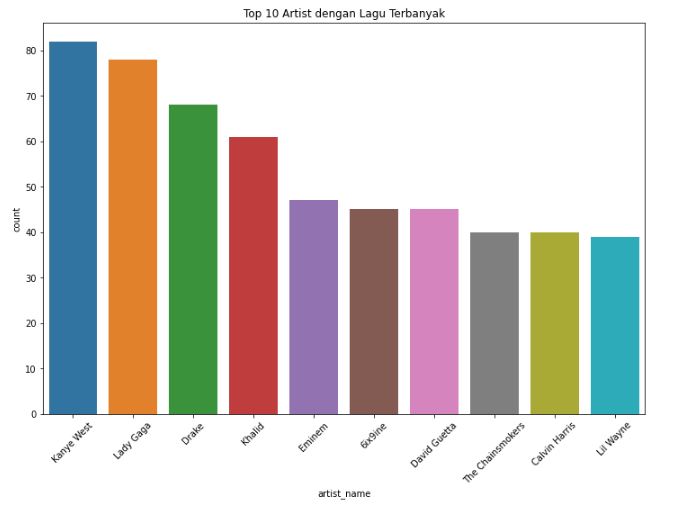
Kemudian berikut adalah visualiasasi terkait jumlah penyayi dan playlist dengan lagu terbanyak dalam dataset ini.
# Top 10 Penyayi dengan lagu terbanyak
plt.figure(figsize=(12,8))
sns.countplot(x='artist_name', data = song_info, order = song_info.artist_name.value_counts().sort_values(ascending=False).iloc[:10].index)
plt.title("Top 10 Artist dengan Lagu Terbanyak")
plt.xticks(rotation = 45)
plt.show()
Output
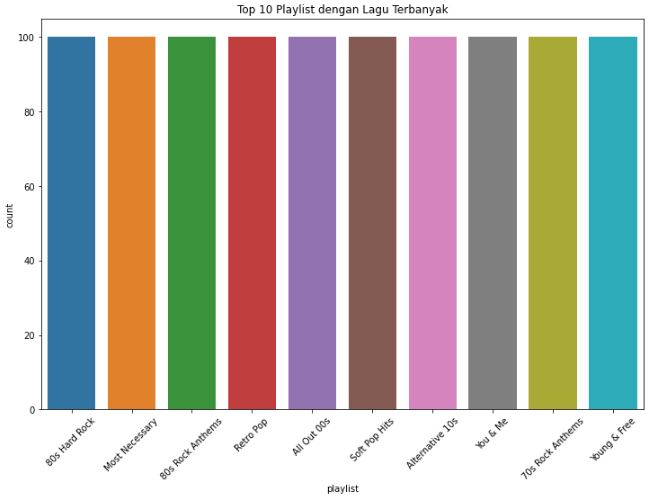
# Top 10 playlist dengan lagu terbanyak
plt.figure(figsize=(12,8))
sns.countplot(x='playlist', data=song_info, order = song_info.playlist.value_counts().sort_values(ascending=False).iloc[:10].index)
plt.title("Top 10 Playlist dengan Lagu Terbanyak")
plt.xticks(rotation = 45)
plt.show()
Output
Data Preparation
Tahap berikutnya adalah data preparation, tahap dimana data akan diolah sehingga sudah siap untuk proses pemodelan. Dan berikut adalah tahapan dalam tahap data preparation:
-
Membuang data duplikasi yang memiliki kesamaan pada kolom
song_namedanartist_name. Tujuannya supaya tidak muncul suatu data sebanyak 2 kali pada proses rekomendasi nanti. Proses penghilangan data duplikasi ini adalah dengan perintah drop_duplicates dari library pandas.
# Membuang data duplikat duplikat song_info = song_info.drop_duplicates(['song_name', 'artist_name']) song_info
-
Membuat fitur baru bernama
infodengan cara menggabungkan kolomartist_name,album_names, danplaylist. Hal tersebut dilakukan untuk memudahkan proses TF-IDF, karena fiturinfotelah mencakup ketiga fitur kolom.
# Menggabungkan kolom artist_name, album_names, dan playlist
new_song_info = song_info.copy()
new_song_info['info'] = new_song_info[['artist_name','album_names','playlist']].agg(' '.join, axis=1)
# Melakukan drop pada kolom artist_name, album_names, dan playlist
new_song_info = new_song_info.drop(columns=['artist_name', 'album_names', 'playlist'], axis = 1)
new_song_info.head()
Pemodelan dan Hasil
Setelah data telah diolah, maka proses selanjutnya adalah pemodelan
TF-IDF
Secara sederhana TF merupakan frekuensi kemunculan kata dalam suatu dokumen. IDF merupakan sebuah perhitungan dari bagaimana kata didistribusikan secara luas pada koleksi dokumen yang bersangkutan. Pada projek ini TF-IDF digunakan pada sistem rekomendasi untuk menemukan representasi fitur penting dari setiap kategori masakan. Untuk melakukan proses TF-IDF ini digunakan fungsi TfidfVectorizer dari sklearn.
# Persiapan tfidfvectorizer tf = TfidfVectorizer() # Melakukan perhitungan idf pada kolom info tf.fit(new_song_info['info']) # Mapping array dari fitur index integer ke fitur nama tf.get_feature_names() # Melakukan fit lagu di translasikan ke bentuk matriks tfidf_matrix = tf.fit_transform(new_song_info['info']) # Melihat ukuran matriks tfidf_matrix.shape # Menjadi bentuk matriks tfidf_matrix.todense()
Cosine similarity
Cosine similarity adalah metrik yang digunakan untuk mengukur tingkat kesamaan suatu dokumen terlepas dari ukurannya. Dan secara matematis, cosine similarity mengukur kosinus sudut antara dua vektor yang diproyeksikan dalam ruang multidimensi. Cosine similarity memiliki keuntungan apabila dua dokumen serupa terpisah oleh euclidean distance karena ukuran dokumen, kemungkinan mereka masih berorientasi ada. Dalam proses ini cosine similarity dipanggil dengan fungsi cosine_similarity dari sklearn. Input fungsi cosine_similarity adalah matrix hasil dari proses TF-IDF, yang kemudian menghasilkan output berupa array tingkat kesamaan.
# Menghitung cosine similarity cos_sim = cosine_similarity(tfidf_matrix) # Membuat dataframe dari variabel cos_sim dengan baris dan kolom berupa song_name cos_sim_df = pd.DataFrame(cos_sim, index=new_song_info['song_name'], columns=new_song_info['song_name'])
Membuat Fungsi song_recommendation
Fungsi tersebut digunakan untuk memberikan rekomendasi berdasarkan sebuah nama lagu. Pada fungsi tersebut akan dilakukan pencarian kolom yang sama dengan nama lagu yang dimasukkan pada dataframe hasil cosine similarity. Setelah itu diurutkan berdasarkan nilai cosine similarity tertinggi, kemudian dilakukan drop nama lagu yang dijadikan acuan agar tidak muncul dalam daftar rekomendasi. Kemudian outputnya berupa 5 lagu yang memiliki cosine similarity tertinggi. Hasil dari fungsi ini dapat dilihat pada gambar berikut :
def song_recommendations(song_name, similarity_data=cos_sim_df, items=song_info, k=5):
print(f"Jika kamu menyukai lagu {song_name}, mungkin kamu juga menyukai 5 lagu berikut :")
# Mengambil data dengan menggunakan argpartition untuk melakukan partisi secara tidak langsung sepanjang sumbu yang diberikan
index = similarity_data.loc[:,song_name].to_numpy().argpartition(range(-1, -k, -1))
# Mengambil data dengan similarity terbaik
closest = similarity_data.columns[index[-1:-(k+2):-1]]
# Drop song_name
closest = closest.drop(song_name, errors='ignore')
return pd.DataFrame(closest).merge(items).head(k)
Pengujian
# Melihat informasi tentang lagu yang akan dijadikan acua
song_info[song_info.song_name.eq('Rap God')]
Output

# Mendapatkan rekomendasi musik song_recommendations(song_name="Rap God")
Output

Evaluasi
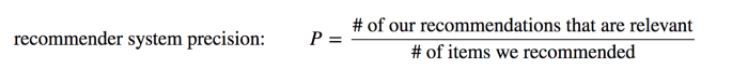
Dan dari perhitungan metriks presisi didapatkan nilai 80%, untuk lebih jelasnya bisa dilihat pada gambar berikut,

Referensi
-
[1]P. Jomsri, S. Sanguansintukul, and W. Choochaiwattana, “A framework for tag-based research paper recommender system: An ir approach,” in 2010 IEEE 24th International Conference on Advanced Information Networking and Applications Workshops, April 2010, pp. 103–108
-
[2]M. Hassan and M. Hamada, “Improving prediction accuracy of multicriteria recommender systems using adaptive genetic algorithms,” in 2017 Intelligent Systems Conference (IntelliSys), Sept 2017, pp. 326–330.
Join the conversation